Du möchtest beim Zeitungsaustragen die optimalen Route kennen, sodass du keine Straße doppelt abgehen musst? In der Mathematik bezeichnet man das Finden eines Kantenzugs im Graphen ohne doppelte Kanten als das Eulertour Problem. Es ist nach dem Mathematiker Leonhard Euler, der 1736 das s.g. Königsberger Brücken Problem löste, benannt.
Der hier vorgestellte Hierholzer Algorithmus löst das Eulertour Problem für Graphen, die eine Eulertour enthalten.
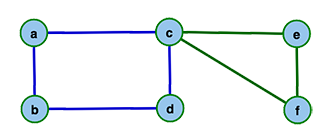
Zweiter Kreis (grün) und komplette Eulertour (a - c - e - f - c - d - b - a)
Das Eulertour Problem
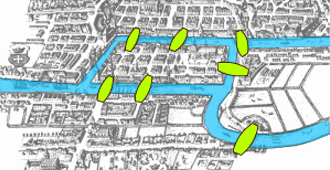
Das Eulertour Problem kam das erste mal im 18. Jahrhundert auf. In der Stadt Königsberg (heute Kaliningrad) gab es zu der Zeit genau sieben Brücken und es stellte sich die Frage, ob man einen Weg oder sogar einen Rundweg finden kann, sodass man alle Brücken genau einmal überquert. Das gleiche Problem ergibt sich auch beim "Haus vom Nikolaus", bei dem man ein Haus in einem Zug, ohne Absetzen des Stiftes zeichnen muss.
In Graphen nennt man diese Fragestellung das Eulertour Problem, benannt nach Leonard Euler. Man versucht eine Folge von Kanten (Kantenzug) so zu finden, dass alle Kanten des Graphen in der Folge genau einmal vorkommen. Wenn man dabei wieder bei dem Knoten ankommt, bei dem man gestartet ist, nennt man diesen Kantenzug Eulertour, andernfalls Eulerweg.
Eulersche Graphen
Leonard Euler fand heraus, welche Voraussetzungen ein Graph erfüllen muss, sodass dieser einen Eulerweg oder eine Eulertour enthält. Hierbei unterscheiden wir von gerichteten und ungerichteten Graphen:
Ungerichtete Graphen
Ein ungerichteter Graph besitzt mind. eine Eulertour, wenn alle seine Knoten einen geraden Grad haben. Das bedeutet, dass alle Knoten genau durch zwei, vier, sechs, ... Kanten mit anderen Knoten verbunden sein müssen. Klar wird dies, wenn man sich Folgendes überlegt: Für jeden Knoten benötigt man genau zwei Kanten, eine um ihn zu erreichen und eine um ihn wieder zu verlassen, bzw. ein Vielfaches davon, je nach dem, wie oft wir den Knoten besucht. Einen Graph der diese Bedingung für alle Knoten erfüllt, nennt man eulerschen Graph.
Für einen Eulerweg kann man diese Bedingung etwas lockern. Und zwar für genau zwei Knoten, deren Grad dann ungerade sein muss. Bei diesen Knoten bleibt dann jeweils eine Kante übrig, sodass man sich ein zusätzliches Mal von dem Knoten entfernen muss bzw. den Knoten besuchen muss. Diese beiden Knoten sind dann genau die Start- und Endknoten des Eulerwegs. Einen solchen Graph nennt man semi-eulersch.
Gerichtete Graphen
Für gerichtete Graphen gelten die die o.g. Regeln weiterhin, man muss nur zusätzlich zwischen eingehenden und ausgehenden Kanten unterscheiden. Hierfür teilt man den Grad eines Knotens in Ingrad und Ausgrad auf. Der Ingrad beschreibt die Anzahl der eingehenden Kanten und der Ausgrad die Anzahl der ausgehenden Kanten. Für einen gerichteten eulerschen Graph muss dann neben dem geraden Grad auch Ingrad gleich Ausgrad für jeden Knoten gelten.
Bei semi-eulerschen Graphen benötigt man weiterhin einen Startknoten mit einer zusätzlichen ausgehenden Kante und einen Zielknoten mit einer zusätzlichen eingehenden Kante.
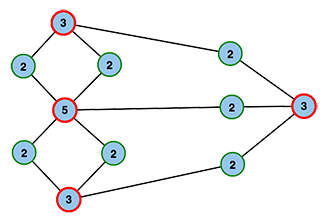
Betrachtet man nun das Königsberger Brückenproblem unter den von Euler gefunden Voraussetzungen, stellt man fest, dass der passende Graph vier Knoten mit einem ungeraden Grad (rot) enthält, sodass es dort weder eine Eulertour noch einen Eulerweg geben kann. Hat man aber einen geeigneten Graphen vorliegen, kann man seine Eulertouren bzw. -wege schließlich mittels des Algorithmus von Hierholzer finden.
Idee des Algorithmus
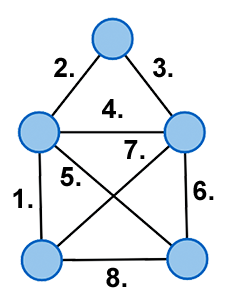
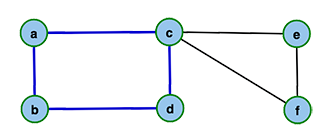
Die Grundidee des Hierholzer Algorithmus ist die schrittweise Konstruktion der Eulertour aus mehreren kantendisjunkten Kreisen. Man beginnt mit einem zufällig ausgewähltem Knoten und folgt dann einer beliebigen bisher unbesuchten Kante des Knotens zu einem weiteren Knoten. Dies wiederholt man, bis man wieder am Startknoten angekommen ist. Durch dieses Verfahren erhält man einen ersten Kreis, genannt Tour. Deckt diese Tour bereits alle Kanten des Graphen ab, ist sie eine Eulertour und der Algorithmus terminiert. Andernfalls sucht man sich einen weiteren Startknoten aus der Menge der Knoten der Tour und bildet einen weiteren Kreis, genannt Subtour. Der neue Kreis enthält nun offensichtlich keine Kanten des ersten Kreises, sie sind also kantendisjunkt. Da sich beide Kreise durch die Wahl des Startknotens aus dem ersten Kreis aber in mindestens einem Knoten schneiden, kann man beide zu einem neuen Kreis zusammenfassen. Dazu betrachtet man die Knotenfolge der Tour und ersetzt den Startknoten der Subtour mit der kompletten Knotenfolge des Kreises. Man erweitert also die ursprüngliche Tour um weitere gefundene Kreise. Schließt die erweiterte Tour nun alle Kanten des Graphen ein, terminiert der Algorithmus, andernfalls kann die Tour noch um eine weitere Subtour erweitert werden.
Im Falle eines ungerichteten semi-eulerschen Graphen startet der Algorithmus mit einem der beiden Knoten mit ungeradem Grad. Im gerichteten Fall genau mit dem Knoten, mit einer zusätzlichen ausgehenden Kante. Eine der gefundenen Subtouren enthält dann keinen Kreis, ist also ein Weg. Wenn die Tour nun um diesen "Subweg" erweitert wird, muss die Erweiterung so erfolgen, dass Anfangs- und Endknoten des Subweges auch Anfangs- und Endknoten der Gesamttour sind.
Was nun?
Einen Graph erstellen und den Algorithmus durchspielen
Sein Wissen an den Forschungsaufgaben testen
1 Von Bogdan Giuşcă unter GNU Free Documentation License 1.2, vgl. Wikimedia.
Eingabe: Ungerichteter Graph G=(V,E), keine oder genau zwei Knoten besitzen einen ungeraden Grad
Ausgabe: Eulertour/-weg als Liste von Knoten
BEGIN
IF Graph ungültig THEN END
IF Graph semi-eulersch THEN
start ← Knoten mit ungeradem Grad
ELSE
start ← beliebiger Knoten
subtour ← ∅
tour ← {start}
REPEAT
start ← Knoten aus tour mit unbesuchten Kanten
subtour ← {start}
akt = start
DO
{akt, u} ← Suche unbesuchte Kante von akt aus
subtour ← subtour ∪ {u}
akt ← u
WHILE start ≠ akt
Integriere subtour in tour
UNTIL tour ist Eulerweg/-tour
END
Wie schnell ist der Algorithmus?
Geschwindigkeit von Algorithmen
Die Geschwindigkeit von Algorithmen wird üblicherweise in der Anzahl an Einzelschritten gemessen, die der Algorithmus bei der Ausführung benötigt.
Einzelschritte sind beispielsweise:
Zuweisungen – Weise Knoten 1 den Wert 20 zu.
Vergleiche – Ist 20 größer als 23?
Vergleich und Zuweisung – Falls 20 größer als 15 ist, setze Variable n auf 20.
Einfache Arithmetische Operationen – Was ist 5 + 5 ?
Da es sehr schwierig sein kann, diese Einzelschritte exakt zu zählen, möchte man nur die ungefähre Größenordnung der Anzahl Schritte wissen. Man spricht auch von der Laufzeit des Algorithmus. Meistens ist es besonders interessant, zu wissen, wie die Geschwindigkeit des Algorithmus von der Größe der Eingabe (hier: Anzahl Kanten und Knoten im Graph) abhängt.
Laufzeit des Hierholzer Algorithmus
Wir gehen von einem Graphen \(G = (V, E)\) mit \(|V| = n\) und \(|E| = m\) aus. Der Algorithmus bestimmt im ersten Schritt eine erste Tour \(T\). Um die nächsten Subtouren zu bestimmen, muss der Algorithmus einen Knoten aus \(T\) finden, der noch unbesuchte Kanten besitzt. Dieser Knoten dient als Start für die folgenden Subtouren mit denen die Tour erweitert wird. Ausgehend von einer leeren initialen Tour, kann die Tour maximal um n Knoten erweitert werden. Nach jeder vollständigen Subtour wird ein neuer Startknoten für folgende Subtouren bestimmt. Bei der Prüfung auf unbesuchte Kanten müssen im ungünstigsten Fall m Kanten betrachtet werden. Damit besitzt der Algorithmus eine polynomielle Laufzeit von \(O(n*m)\).
Der Algorithmus kann weiter optimiert werden, indem man eine separate Adjazenzliste speichert, aus der bereits genutzte Kanten gelöscht werden. So muss man zur Überprüfung auf unbesuchte Kanten pro Knoten nicht jedes Mal alle Kanten betrachtet, sondern insgesamt jede Kante nur ein einziges Mal. Damit ist eine lineare Laufzeit von \(O(n+m)\) möglich.
Die gleiche Laufzeit wird außerdem benötigt, um zu prüfen, ob ein Graph eulersch ist und der Hierholzer Algorithmus überhaupt angewendet werden kann.
Wo finde ich noch mehr Informationen zu Graphalgorithmen?
Ein letzter Hinweis zum Ziel und Inhalt dieser Seite und zu Zitationen
Der Lehrstuhl M9 der TU München beschäftigt sich mit diskreter Mathematik, angewandter Geometrie und der mathematischen Optimierung von angewandten Problemen. Die hier dargestellten Algorithmen sind sehr grundlegende Beispiele für Verfahren der diskreten Mathematik (die tägliche Forschung des Lehrstuhls geht weit darüber hinaus). Die vorliegenden Seiten sollen SchülerInnen und Studierenden dabei helfen, diese auch im realen Leben sehr wichtigen Verfahren (besser) zu verstehen und durch Ausprobieren zu durchdringen. Aus diesem Grund konzentriert sich die Darstellung bewusst auf die Ideen der Algorithmen, und präsentiert diese oftmals unter weitestgehendem Verzicht auf mathematische Notation.
Bitte beachten Sie, dass diese Seiten im Rahmen von studentischen Arbeiten unter Betreuung des Lehrstuhls M9 erstellt wurden. Den dabei entstandenen Code und die zugehörige Darstellung können wir nur punktuell überprüfen, und können deshalb keine Garantie für die vollständige Korrektheit der Seiten und der implementierten Algorithmen übernehmen.
Selbstverständlich freuen wir uns über jegliches (auch kritisches) Feedback bezüglich der Anwendungen sowie eventuellen Ungenauigkeiten und Fehlern der Darstellung und der Algorithmen. Bitte nutzen Sie hierzu den Anregungen-Link, welcher auch rechts in der Fußleiste zu finden ist.
Um diese Seite zu zitieren, nutze bitte die folgenden Angaben:
Titel: Der Hierholzer Algorithmus
Autoren: Mark J. Becker, Wolfgang F. Riedl; Technische Universität München




{kind=link}